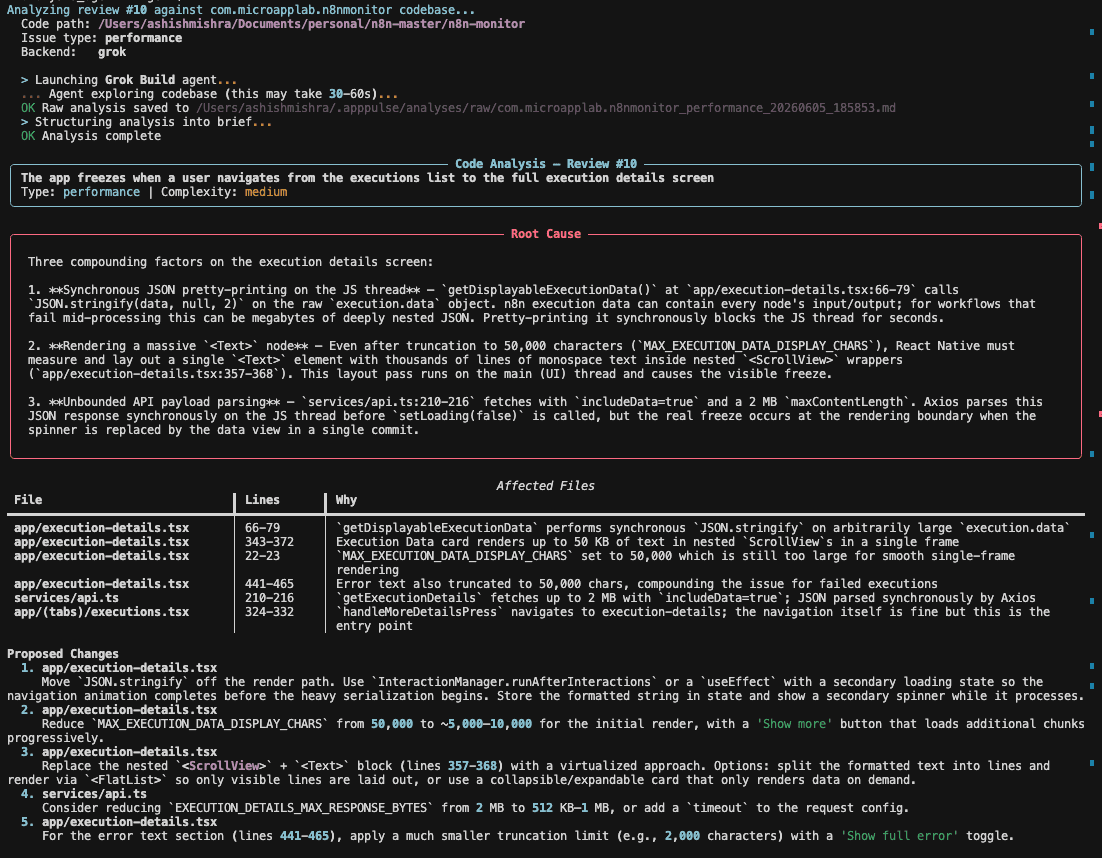
NodeJs : Streams and Buffers
Streams are vital in Node.js because they allow you to process data in small, manageable chunks instead of loading it all into memory at once. This makes Node.js incredibly memory-efficient and capable of handling I/O operations on very large datasets, like file processing or network communication, without crashing.
The Role of Buffers
Before diving into streams, it's essential to understand Buffers. Think of a Buffer as a temporary holding spot for a chunk of binary data. When a stream reads data from a source (like a file), it doesn't get the whole file at once; it gets a small piece and stores it in a Buffer.
A Buffer is Node.js's way of representing a fixed-size region of physical memory. It's like a small, fast bucket for raw data. Streams are the pipes that move these buckets around efficiently.
The Four Types of Node.js Streams
Streams are one of the fundamental concepts that make Node.js so powerful for I/O-heavy operations. There are four main types of streams you'll encounter.
1. Readable Streams
These are streams from which you can read data. They are the source.
Analogy: A water faucet 🚰. You can only get water out of it; you can't put water into it.
Examples:
fs.createReadStream()for reading a file, therequestobject on an HTTP server (for receiving uploads), orprocess.stdin.
2. Writable Streams
These are streams to which you can write data. They are the destination.
Analogy: A sink drain. You can only pour water into it.
Examples:
fs.createWriteStream()for writing to a file, theresponseobject on an HTTP server (for sending data to a client), orprocess.stdout.
3. Duplex Streams
These are streams that are both Readable and Writable.
Analogy: A telephone handset 📞. You can speak into it (Writable) and listen from it (Readable) at the same time.
Examples: A TCP socket, which allows for two-way communication over a network.
4. Transform Streams
These are a special type of Duplex stream that can modify or transform data as it's being written and read.
Analogy: A water filter. Water goes in (Writable), is changed (transformed), and clean water comes out (Readable).
Examples: The
zlibstream for compressing/decompressing data, or thecryptostream for encrypting/decrypting data.
Understanding Backpressure
Backpressure is a crucial concept for a senior developer. It's a built-in mechanism that handles a common problem: what happens when the Readable stream is much faster than the Writable stream?
Imagine you're reading a huge file (fast Readable faucet) and writing it over a slow network (slow Writable drain). Without backpressure, the fast reader would produce data much faster than the writer could consume it, causing your application's memory usage to explode as data gets buffered indefinitely.
Streams solve this automatically:
Every stream has a buffer with a limit called
highWaterMark.When a Writable stream's buffer fills up past this mark, its
.write()method will returnfalse.This
falsesignal is sent back to the Readable stream, telling it: "Hey, I'm overwhelmed! Please pause reading."The Readable stream will stop reading from the source.
Once the Writable stream has processed its backlog and its buffer is clear, it emits a
'drain'event.The Readable stream listens for this
'drain'event and, upon hearing it, resumes reading.
This elegant push-and-pull mechanism ensures data flows smoothly without overwhelming the system's memory. The .pipe() method handles all of this for you automatically.
Script: Transform a Large CSV File
Here is a practical example that ties everything together. This script reads a large CSV, converts the name column to uppercase, and writes the result to a new file, all without loading the entire file into memory.
Let's assume you have a large.csv file that looks like this:
Code snippet
id,name,email
1,john doe,john@example.com
2,jane smith,jane@example.com
... (millions of rows) ...
Here's the Node.js script:
JavaScript
const fs = require('fs');
const { Transform } = require('stream');
const sourcePath = './large.csv';
const destinationPath = './processed.csv';
// 1. Create a Readable stream from the source file
const readableStream = fs.createReadStream(sourcePath, { encoding: 'utf-8' });
// 2. Create a Writable stream for the destination file
const writableStream = fs.createWriteStream(destinationPath);
// 3. Create a custom Transform stream
const csvToUpperTransformer = new Transform({
transform(chunk, encoding, callback) {
// chunk is a Buffer. Convert it to a string.
const dataString = chunk.toString();
const lines = dataString.split('\n');
const transformedLines = lines.map((line, index) => {
// Assuming first line is the header, don't change it.
// This is a simplified CSV parser. For production, use a library.
if (index === 0 && !this.headerProcessed) {
this.headerProcessed = true;
return line;
}
const columns = line.split(',');
// Check if the line has enough columns to avoid errors
if (columns.length > 1) {
columns[1] = columns[1].toUpperCase(); // Transform the 'name' column
}
return columns.join(',');
});
// Push the transformed data to the next stream
this.push(transformedLines.join('\n'));
// Tell the stream we are done with this chunk
callback();
}
});
// Add a flag to handle the header correctly across multiple chunks
csvToUpperTransformer.headerProcessed = false;
// 4. Pipe the streams together!
console.log('Starting CSV processing...');
readableStream
.pipe(csvToUpperTransformer)
.pipe(writableStream)
.on('finish', () => {
console.log('✅ Processing complete! Check processed.csv.');
})
.on('error', (error) => {
console.error('An error occurred:', error);
});
This is the magic of streams. The data flows from the reader, through the transformer, to the writer in small chunks. At no point is the entire large.csv stored in RAM.
Questions
"Why are streams important in Node.js?"
Streams are important for three key reasons:
Memory Efficiency: This is the biggest one. They allow you to work with data of any size without being limited by your available RAM. This is fundamental to Node's design philosophy.
Time Efficiency: You can start processing data as soon as the first chunk arrives, rather than waiting for the entire payload to be downloaded or read. This leads to faster and more responsive applications.
Composability: The
.pipe()method provides an elegant way to connect different stream-based operations, much like the pipe (|) operator in Linux/Unix. This makes code clean, readable, and easy to reason about.
"How would you use them to handle a large file upload?"
This is a classic use case. In a web framework like Express or Fastify, the incoming request object (req) is a Readable stream containing the uploaded file data.
Here's the senior-level approach to handling it:
Direct Piping to Disk: The simplest method is to pipe the request stream directly to a file system Writable stream.
JavaScript
app.post('/upload', (req, res) => { const filePath = path.join(__dirname, 'uploads', 'large-file.zip'); const writableStream = fs.createWriteStream(filePath); // req is the Readable stream of the upload req.pipe(writableStream); req.on('end', () => { res.status(200).send('File uploaded successfully!'); }); writableStream.on('error', (err) => { console.error('Error writing file:', err); res.status(500).send('Error saving file.'); }); });Transforming During Upload: For more advanced scenarios, you can pipe the upload through one or more Transform streams before saving it. This is incredibly powerful.
JavaScript
const zlib = require('zlib'); const crypto = require('crypto'); app.post('/upload-secure', (req, res) => { const filePath = path.join(__dirname, 'uploads', 'encrypted.zip.gz'); const key = crypto.randomBytes(32); // Store this key securely! const iv = crypto.randomBytes(16); const gzip = zlib.createGzip(); const cipher = crypto.createCipheriv('aes-256-cbc', key, iv); const writableStream = fs.createWriteStream(filePath); // Chain the pipes: Upload -> Gzip -> Encrypt -> File req .pipe(gzip) .pipe(cipher) .pipe(writableStream); req.on('end', () => res.status(200).send('File uploaded and encrypted!')); });
This second example shows true mastery of the stream API, handling compression and encryption on-the-fly with minimal memory overhead, which is exactly what makes Node.js so well-suited for high-performance network applications.