The Core Web Vitals Playbook: A Deep Dive into LCP, INP, and CLS.
The Core Web Vitals Playbook: Engineering for Speed, Stability, and Responsiveness
Introduction: The Real Cost of Ignoring Web Vital Metrics
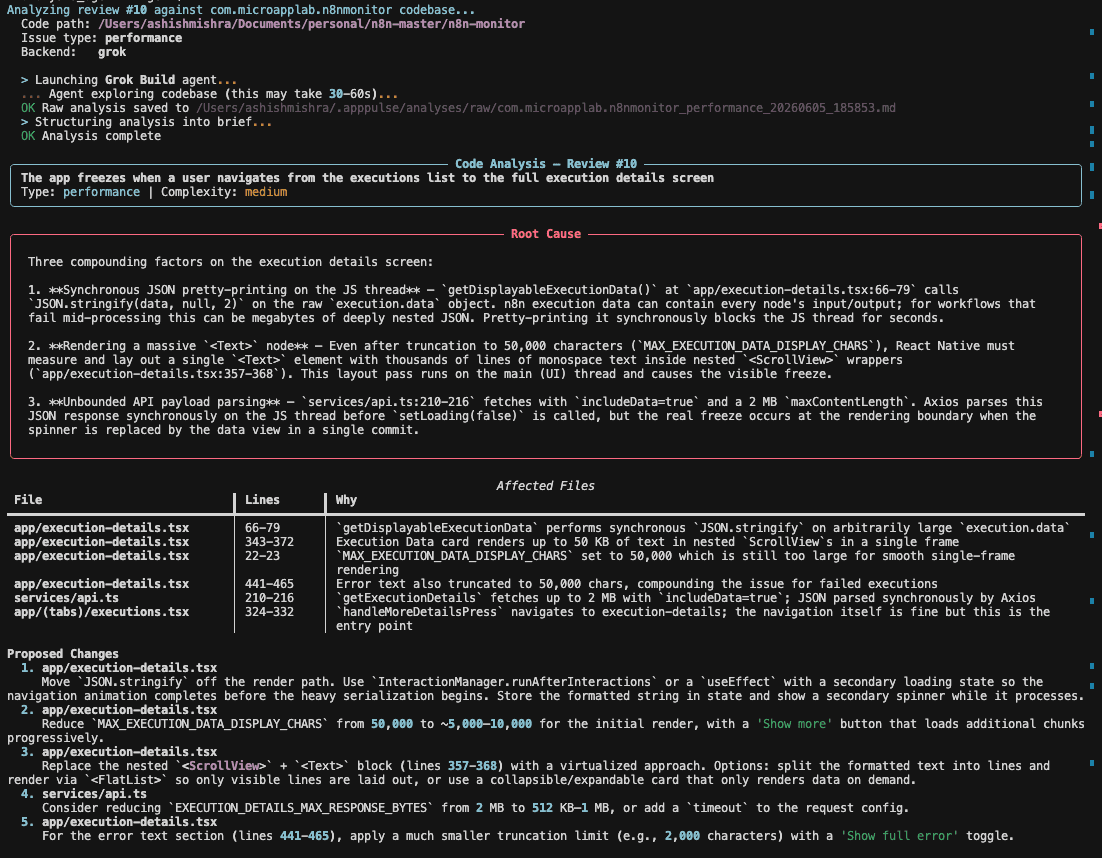
Imagine this: your team deploys a beautiful, responsive front-end with modern components and optimized assets. Lighthouse audit scores look great. But somehow, user engagement is down, bounce rates are up, and key conversions drop by 15%.
You dig deeper and discover that while Time to Interactive (TTI) and First Contentful Paint (FCP) are within thresholds, your real user experience is tanking. Layouts shift unexpectedly during load. Buttons freeze after users click. Pages take ages to visually settle, especially on mid-tier mobile devices.
The problem? Poor Core Web Vitals.
- LCP (Largest Contentful Paint): Too slow
- INP (Interaction to Next Paint): Unpredictable responsiveness
- CLS (Cumulative Layout Shift): Visual instability during critical engagement windows
Unlike traditional performance metrics that focus on load speeds in isolation, Core Web Vitals align with what users feel.
They measure what actually matters in production.
The Technical Challenge: Why Traditional Metrics Fail
Most front-end teams have historically optimized for the wrong goals:
- Bundle size shrinkage
- JS execution time
- First Paint / First Byte
These aren't useless, but they don't correlate directly to user perception of performance.
Let’s look at a real case:
- Homepage LCP crossed 4 seconds on mobile
- INP spiked to 350ms on pages with complex modals
- CLS of 0.25 due to image carousels and injected banners
Each of these issues persisted despite optimizing for Lighthouse or WebPageTest benchmarks.
Traditional metrics missed what the new ones catch:
- When interaction feels sluggish
- When content visibly jumps and breaks workflow focus
- When the primary content actually becomes viewable
Unlocking Stability and Speed with the Core Web Vitals Playbook
Core Web Vitals aren't just a checklist. They represent a mindset shift in front-end and performance tooling.
LCP: Optimize For the Hero Experience
Common root issues:
- Lazy-loaded hero images
- Web fonts rendering late
- Non-critical JS blocking image paint
Fixes:
- Use
<link rel="preload">for hero images and fonts - Defer non-critical scripts
- Leverage
priorityflag in Next.jsImagecomponent
INP: Building for Snappy Interaction
Symptoms: Button clicks, dropdowns, modals feel sluggish.
Root causes:
- React state updates triggering re-renders
- Handlers blocked by long tasks
Fixes:
- Break long tasks with
requestIdleCallback - Prioritize input responsiveness over paint timing
- Use
useTransitionfrom React 18 when handling deferred updates
CLS: Design for Layout Predictability
Causes:
- Images without width/height
- Ad slots or third-party widgets injecting dynamically
- Web fonts swapping mid-render
Fixes:
- Always reserve space via aspect ratio boxes
- Use
font-display: optionalwith fallbacks - Precalculate layout for injected components
Architectural Blueprint: Building for Better Web Vitals
Core Web Vitals must be part of the front-end architecture. This means:
- Accurate monitoring in CI/CD and real user monitoring (RUM)
- A/B testing not just features, but layout and LCP candidates
- Regression prevention using synthetic metrics
Here’s a sample architecture:
Components:
- Lighthouse CI -> Synthetic budget enforcement
- Web-vitals.js -> Capture user events
- GrailMetrics or Calibre -> Real-user monitoring charts
- Rollup or Webpack analyzer -> Bundle accountability
import {getCLS, getFID, getLCP, getINP} from 'web-vitals';
getLCP(console.log);
getINP(console.log);
getCLS(console.log);
This snippet adds low-cost in-page monitoring that sends metrics to your analytics function.
IDEALLY, tie this into a logging pipeline to monitor regressions pre-and post-deploy.
Tools like next/script, next/image, and frameworks like Astro give more control over render priority and interaction payloads.
Conclusion: Performant Sites Are Built, Not Optimized
If you're still treating Web Vitals like after-the-fact audits, expect issues to leak into production.
Instead, bake it into your architecture. Measure what users actually experience. Set budgets. Alert early.
This playbook isn’t magic. But it will empower any front-end team to build applications that feel seamless , fast, stable, and responsive.
What changes in your front-end stack would provide the biggest impact on user-perceived performance?
Are you set up to measure LCP and INP during development or only post-release?
What’s causing your biggest CLS debt , and can you afford to leave it unsolved?