I built a very cheap App Review analysis pipeline that also finds Bugs in my app code
I got tired of reading app reviews manually every morning, so I built a command-line tool that pulls reviews from Google Play and the App Store, classifies them (bug, feature request, crash, praise), and sends me a daily summary. It costs about $0.50/month. In version 2, I added the ability to point it at my source code and get an analysis: which files are causing the bug, what to change, and how complex the fix is.
If you need to checkout code for your own setup : https://github.com/Mr-Ashish/AppPulse
The Problem
I have a few apps on Google Play. Every morning, I'd open the Play Console, scroll through new reviews, and try to figure out:
- Is this a bug or a complaint?
- Is this the same issue three other people mentioned yesterday?
- Does this match any of the crashes I'm seeing in Firebase?
About 15 minutes of work. But it's unfocused work. Scanning text, making mental classifications, switching between tabs. On days with 20+ reviews, I'd either rush through them or skip the whole exercise.
I wanted a morning briefing:
"You got 12 new reviews. 3 are bugs (1 critical, photo upload crashes on large images). 2 are feature requests. 7 are praise. The critical bug matches a Firebase crash that affected 312 users this week."
So I built one.
Version 1: Classify and Digest
The Flow
Google Play ──┐
→ Pull new reviews→Classify review → Save to database
App Store ───┘ │ (using AI)
│
Firebase/Sentry ──────
---------------------------------------------------------------
↓
Daily Digest ┌──────────────────┐
│ 3 bugs (1 critical)
│ 2 feature requests
│ 7 praise
│ Top crash: OOM in
│ ImageUploadService
└──────────────────┘
↓ ↓
Terminal Slack
Classification
Each review goes through an LLM (a language model; I use OpenAI's gpt-4o-mini, their cheapest option). The LLM reads the review text and categorizes it:
| Category | Meaning | Example review |
|---|---|---|
| bug | Something broken | "Upload button does nothing after I pick a photo" |
| crash | App closes or freezes | "App crashes every time I open settings" |
| feature_request | User wants something new | "Please add dark mode" |
| performance | Slow, laggy, battery drain | "App drains 20% battery in an hour" |
| praise | Positive feedback | "Best app I've used for this!" |
| complaint | General dissatisfaction | "Used to be good, now it's terrible" |
Along with the category, the LLM extracts:
- Severity (critical, major, or minor)
- Keywords (the specific feature or area mentioned, e.g., "photo upload", "settings screen")
- Functional area (which part of the app is affected)
Reviews go to the LLM in batches of 10, so one API call classifies 10 reviews at once. That's what keeps the cost low.
Cost
For an app with about 500 reviews per week:
| Component | Monthly Cost |
|---|---|
| Google Play API | Free |
| App Store Connect API | Free |
| Firebase/Sentry API | Free (free tier) |
| OpenAI classification (~2,000 reviews/month) | ~$0.50 |
| Storage (SQLite, local file) | Free |
| Total | ~$0.50/month |
If you use Ollama (runs AI models on your own computer), the cost drops to $0.00/month.
The Tech Stack
- Python , the whole tool is a Python command-line app
- Click , a library for building command-line interfaces (handles
apppulse run,apppulse reviews, etc.) - SQLAlchemy + SQLite , stores everything in a single local database file at
~/.apppulse/data.db - Rich , makes the terminal output clean with tables, colors, and panels
- OpenAI / Anthropic / Ollama , LLM providers for classification (you pick one during setup)
No servers. No cloud infrastructure. No Docker. Run pip install and a 5-minute setup wizard.
A Typical Morning
$ apppulse run
# Pulling reviews for MyApp Android... 12 new reviews
# Classifying... done (0.8s)
# Pulling crash data from Firebase... 3 active crashes
# Correlating reviews with crashes... 1 match found
# ── Daily Digest ───────────────────────────────────────
# 12 new reviews: 3 bugs (1 critical), 2 feature requests, 7 praise
#
# 🔴 Critical: Photo upload crashes for >10MB images
# → Matches Firebase crash: OutOfMemoryError (312 users affected)
# → 3 reviews mention this issue
#
# 🟡 Major: Search doesn't update after applying filters
# → 2 reviews
#
# 💡 Feature requests: Dark mode (2 requests)
Five seconds. I know what matters. No tab-switching, no scrolling through the Play Console.
Version 2: From Classification to Code Analysis
Version 1 told me what users were experiencing. It didn't tell me where in my code the problem lived or what to change.
For the critical bug above, "Photo upload crashes for >10MB images," I'd still need to:
- Open the project
- Search for upload-related code
- Look at the Firebase stacktrace
- Connect the dots
- Figure out a fix
So I built a second stage: code analysis.
The Mechanism
apppulse analyze 42
│
▼
┌────────────────────────────────┐
│ Load the review from the │
│ database + crash data │
└───────────────┬────────────────┘
│
▼
┌────────────────────────────────┐
│ AI agent explores your │
│ source code with read-only │
│ tools (search, read files, │
│ find function definitions) │
└───────────────┬────────────────┘
│
▼
┌────────────────────────────────┐
│ Produces an Analysis Brief │
│ • Root cause │
│ • Affected files + lines │
│ • Proposed changes │
│ • Complexity estimate │
│ • Testing notes │
└────────────────────────────────┘
You point AppPulse at your app's source code folder during setup. Running apppulse analyze 42 (where 42 is a review ID) triggers the AI agent to:
- Read the review and any matched crash data
- Get a structural overview of your project (a map of every file and its key classes/functions)
- Search the code for relevant keywords, error messages, class names, the feature area mentioned in the review
- Read the specific files that look promising
- Produce a structured analysis with file paths, line numbers, and proposed changes
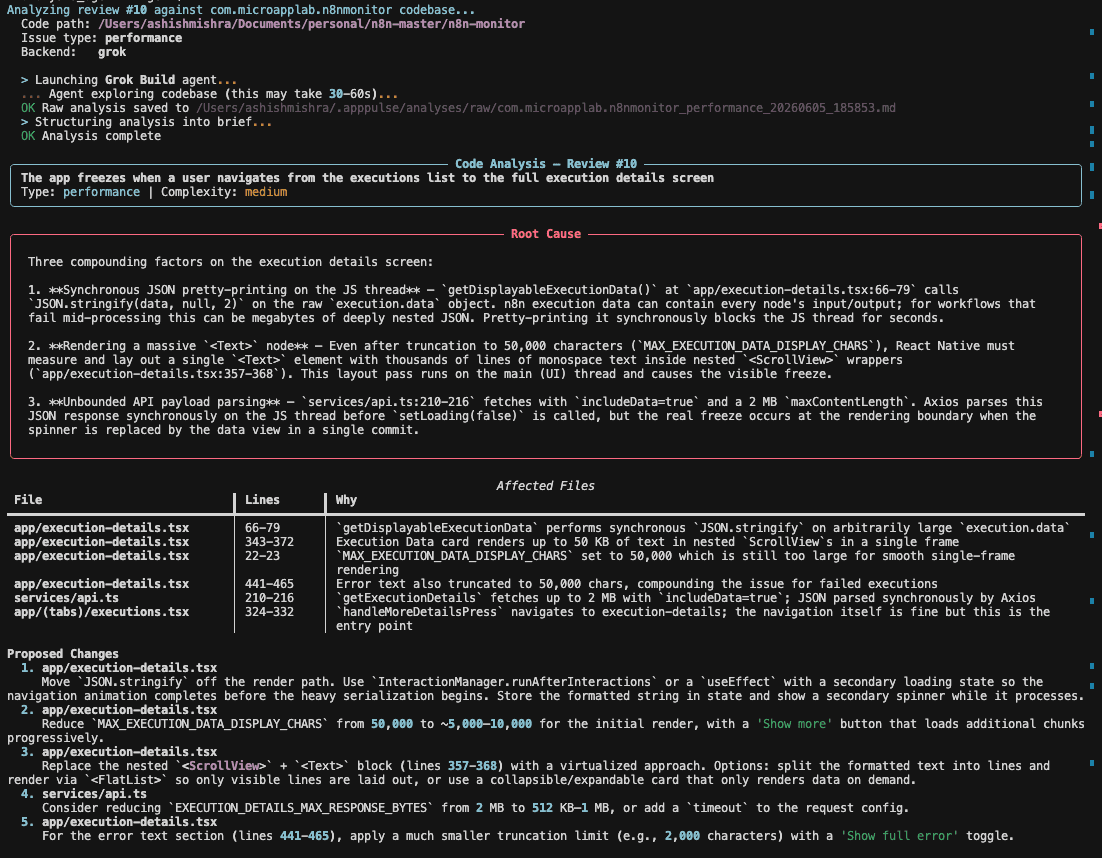
The Output
┌──────────────────────────────────────────────────────────────┐
│ CODE ANALYSIS — Review #42 │
│ Photo upload crashes for >10MB images │
│ Type: bug │ Complexity: medium │
├──────────────────────────────────────────────────────────────┤
│ │
│ ROOT CAUSE │
│ ImageUploadService.compress() loads the full image into │
│ memory. Images >10MB exceed the memory limit on phones │
│ with ≤4GB RAM, causing the app to crash. │
│ │
│ AFFECTED FILES │
│ ImageUploadService.java (lines 45-89) — compress() method │
│ ImageUtils.java (lines 12-35) — no file size check │
│ │
│ PROPOSED CHANGES │
│ 1. Resize large images before loading them into memory │
│ 2. Add a file size check before compression starts │
│ 3. Use streaming compression instead of loading everything │
│ into memory at once │
│ │
│ TESTING NOTES │
│ Test with 1MB, 10MB, and 50MB images on a low-memory device │
└──────────────────────────────────────────────────────────────┘
Instead of a category label, I get the file, the line, what to change, and how to test it.
Pick Your Analysis Engine
The analysis engine is pluggable. I built it with four options:
| Backend | Description | Good for |
|---|---|---|
| Built-in | A lightweight AI agent that runs inside AppPulse, using PydanticAI (a Python framework for building AI agents with structured output) | Quick analyses, small codebases |
| Grok Build | xAI's coding assistant in headless mode | Fast, targeted exploration |
| Claude Code | Anthropic's coding assistant in headless mode | Deep multi-file investigations |
| OpenAI Codex | OpenAI's coding assistant | Sandboxed, autonomous mode |
The external backends (Grok, Claude Code, Codex) use a two-stage approach:
- The coding assistant explores the codebase and writes its findings as a markdown document
- A cheap AI call ($0.001) extracts that document into the structured analysis format
Consistent output regardless of which AI did the exploration. Adding a new backend takes about 20 lines of code.
Switching is one line in the config file:
code_analysis:
enabled: true
backend: "grok" # or "builtin", "claude_code", "codex"
Lessons
1. Classify before you analyze
Categorization (bug vs. feature request vs. praise) determines everything downstream. Code analysis needs good classification as input, or it wastes time investigating a feature request as if it were a bug.
2. Cheap AI models handle most of this
The classification pipeline runs on gpt-4o-mini, OpenAI's cheapest model. For categorizing app reviews, which are 1-3 sentences, it's accurate enough. Expensive models are overkill.
3. Give the AI a map of your codebase
The biggest analysis quality improvement came from generating a project map upfront, a compact overview of every file and its key components. Without the map, the AI spent most of its budget figuring out where things lived. With it, the AI goes to the relevant files on its first move. A GPS for the codebase.
4. Save raw output
Every analysis saves the AI's raw output as a markdown file. If the structured summary looks off, I can check what the AI found and pinpoint whether the problem was in the exploration or the extraction.
5. No infrastructure required
The whole tool runs as a single command-line app. The database is a SQLite file on disk. The cache is a text file. No server, no Docker container, no cloud deployment. I run apppulse run by hand or on a daily schedule.
Up Next
- Batch analysis , analyze all critical bugs at once instead of one at a time
- Per-app configuration , different analysis settings for different apps
- Auto-analysis , run code analysis on critical bugs during the daily pipeline, so the morning digest includes root causes alongside classifications
- Tracking outcomes , connect analyses to fixes, so the tool can learn which investigations led to successful resolutions
The classification half took a weekend. Code analysis took another. The pipeline costs less per month than a cup of coffee, and it replaced 15 minutes of unfocused tab-switching with a 5-second terminal readout.