Building an App Review Intelligence Pipeline + Creates GitHub Issues Automatically
TL;DR: Use the official Google Play Publisher API and App Store Connect API to pull your own app's reviews on a schedule, classify each review with a cheap LLM call (bug/feature request/crash/praise), cluster similar ones, and auto-create GitHub Issues with device data, severity, and even a codebase-level root cause analysis attached.
Most mobile teams check app reviews manually — maybe once a week, maybe during a crisis. The information is there: users tell you exactly what's broken, on which devices, and what they wish your app could do. But that signal sits in two different consoles, buried under 5-star "great app!" noise, and never makes it into your issue tracker until someone copies it by hand.
This post walks through how to build a pipeline that closes that loop automatically.
The Problem
App store reviews are one of the most direct feedback channels you have. Users tell you:
- What's crashing (and on which device)
- What features they want
- What your last update broke
But this data is scattered across two platforms (Google Play Console and App Store Connect), mixed in with unhelpful noise, and completely disconnected from where your team actually works — GitHub Issues, sprint boards, Slack channels.
The goal: a system that runs every few hours, pulls new reviews, figures out what matters, and creates pre-triaged issues in your GitHub repo — complete with device breakdowns and severity labels.
What I Considered
Option 1: SaaS Tools (Appbot, AppFollow, AppTweak)
Tools like Appbot (trained on 400M+ reviews, 93% sentiment accuracy), AppFollow, and AppTweak already solve the analysis side. They pull from both stores, classify sentiment, cluster topics, and give you dashboards.
Verdict: Good for analysis, but none of them create GitHub Issues from review clusters. You'd still need a bridge from their output to your issue tracker. Pricing starts at $50-160/month and scales with volume. Worth considering if you just want dashboards and don't need the GitHub integration.
Option 2: Open-Source Analysis Repos
Four repos stand out:
- Automated_User_Feedback_Analysis — BERTopic + VADER, Jupyter notebooks
- Review-Analyzer — BERTopic + XLM-RoBERTa + BART summarization, Streamlit UI
- ai-review-analysis-pipeline — GPT-4o-mini classification, FastAPI + Streamlit
- app-reviews-nlp — LDA + NMF + multiple sentiment approaches
Verdict: Strong on the analysis side. But every one of them assumes data already exists (you upload a CSV), runs as a one-shot analysis (not a scheduled pipeline), has no GitHub integration, and ignores device/OS metadata entirely. They answer "what are users saying?" but not "what should my team work on next?"
Option 3: Build a Custom Pipeline on Official APIs
Use the Google Play Publisher API and App Store Connect API (which you have access to since these are your own apps), add LLM classification, clustering, and a GitHub bridge layer.
Verdict: More work upfront, but you get exactly what you need: continuous monitoring, device-level correlation, and automatic issue creation. The analysis part isn't novel — the value is in the operational wrapper.
Key insight: The NLP/classification techniques in the open-source repos are solid and well-proven. What's missing everywhere is the plumbing: pulling data reliably on a schedule, correlating with device metadata, and bridging from "insight" to "actionable work item in GitHub."
The Solution
Architecture Overview
The pipeline has five stages:
Reviews (Google Play + App Store)
→ Ingestion (official APIs, every 6 hours)
→ Storage (PostgreSQL/SQLite, deduplicated)
→ Analysis (LLM classification + embedding-based clustering)
→ GitHub Bridge (issue creation with deduplication)
→ Reporting (alerts on spikes, weekly digests)
Stage 1: Pulling Reviews from Official APIs
Google Play uses a Service Account with OAuth 2.0. The endpoint:
GET /androidpublisher/v3/applications/{packageName}/reviews
Each review includes starRating, text, device, androidOsVersion, appVersionName, deviceMetadata (manufacturer, model, RAM), and timestamps. This device-level data is gold — it's how you spot "this crashes on Samsung Galaxy S24 + Android 15 specifically."
Watch out: The Google Play API only returns reviews from roughly the last 7 days. It's not a historical archive. You must poll daily at minimum and store everything yourself. For historical backfill, download CSV reports from the Play Console.
Apple App Store uses JWT authentication (ES256 algorithm) with a .p8 private key. The endpoint:
GET /v1/apps/{appId}/customerReviews?sort=-createdDate&limit=200
Returns rating, title, body, reviewer nickname, creation date, and territory.
Watch out: Apple's API does not return device or OS information per review. You get the country and app version, but not "iPhone 15 Pro running iOS 18." To tie iOS issues to specific devices, you'd need to correlate with crash reports from a separate system (Crashlytics, Sentry, etc.).
Incremental sync strategy: Store last_seen_review_id and last_poll_timestamp per store. On each run, fetch newest-first and stop when you hit a review already in your database.
Stage 2: Storage Schema
Reviews land in a unified schema regardless of which store they came from:
CREATE TABLE reviews (
id SERIAL PRIMARY KEY,
store TEXT NOT NULL, -- 'google_play' or 'app_store'
store_review_id TEXT NOT NULL,
text TEXT,
rating INTEGER,
review_date TIMESTAMP,
device TEXT, -- null for App Store
os_version TEXT, -- null for App Store
app_version TEXT,
country TEXT,
language TEXT,
raw_json JSONB,
-- analysis results (filled by Stage 3)
category TEXT, -- bug, feature_request, crash, etc.
severity TEXT, -- critical, major, minor, none
sentiment TEXT,
summary TEXT,
keywords JSONB,
functional_area TEXT,
processed_at TIMESTAMP,
UNIQUE(store, store_review_id)
);
Two additional tables track clusters and their GitHub issue links:
CREATE TABLE clusters (
id SERIAL PRIMARY KEY,
category TEXT, -- bug or feature_request
summary TEXT,
review_count INTEGER,
avg_rating REAL,
first_seen TIMESTAMP,
last_seen TIMESTAMP,
status TEXT DEFAULT 'open', -- open, resolved, ignored
github_issue_number INTEGER, -- the bridge to GitHub
github_issue_url TEXT
);
CREATE TABLE cluster_reviews (
cluster_id INTEGER REFERENCES clusters(id),
review_id INTEGER REFERENCES reviews(id),
PRIMARY KEY (cluster_id, review_id)
);
The clusters.github_issue_number column is what prevents the pipeline from creating 50 duplicate issues for the same bug. When new reviews match an existing cluster that already has a linked issue, the pipeline appends a comment to that issue instead.
Stage 3: LLM Classification
For each unprocessed review, one LLM call classifies it:
CLASSIFICATION_PROMPT = """Classify this app review. Return JSON only.
Review: "{review_text}"
Rating: {rating}/5
Device: {device}
OS: {os_version}
App version: {app_version}
{
"category": "bug | feature_request | crash | performance | ux_issue | praise | complaint | other",
"severity": "critical | major | minor | none",
"sentiment": "positive | negative | neutral | mixed",
"summary": "one-line description of the core issue or request",
"keywords": ["keyword1", "keyword2"],
"functional_area": "auth | media | payments | search | onboarding | notifications | settings | other"
}"""
This works because review text is short (typically 1-3 sentences), the categories are well-defined, and modern small models (GPT-4o-mini, Claude Haiku) handle this classification with ~95% accuracy at roughly $0.50-1.00 per 10,000 reviews.
After classification, reviews are embedded (using sentence-transformers or OpenAI's text-embedding-3-small) and clustered by cosine similarity. Reviews with >0.85 similarity to each other get grouped. "App crashes when uploading photos," "crash on photo upload every time," and "photo upload makes app close" all land in the same cluster.
Stage 4: The GitHub Bridge
This is where the pipeline goes from "analysis tool" to "operational system."
Threshold-based triggers:
- Bug cluster with ≥3 similar reviews → create a GitHub Issue labeled
bug+user-reported - Feature request cluster with ≥5 requests → create an issue labeled
enhancement+user-reported - Any single 1-star review mentioning "crash" → immediate issue labeled
critical
Deduplication: Before creating an issue, embed the cluster summary and compare it against all open issues labeled user-reported. If similarity exceeds 0.85, append a comment to the existing issue with the updated review count instead of creating a duplicate.
What the generated issue looks like:
## [User Reviews] App crashes during photo upload (47 reports)
**Source**: 47 reviews (32 Google Play, 15 App Store)
**Period**: June 15–28, 2025
**Average Rating**: 1.3★
**Severity**: Critical
### Affected Devices (Google Play data)
| Device | OS | App Version | Count | Avg Rating |
|--------|-------|---------|-------|------------|
| Samsung Galaxy S24 | Android 15 | 3.2.1 | 18 | 1.2★ |
| Pixel 8 | Android 15 | 3.2.1 | 9 | 1.4★ |
### Representative Reviews
> "Every time I try to upload a photo larger than about 10MB the
> app just closes. Started after the last update." — ★1, Samsung S24
### Keywords
crash, photo, upload, large file, close, update
This shows up in your GitHub Issues tab, fully triaged, with device data and representative quotes. Your team can start working immediately without ever opening the Play Console.
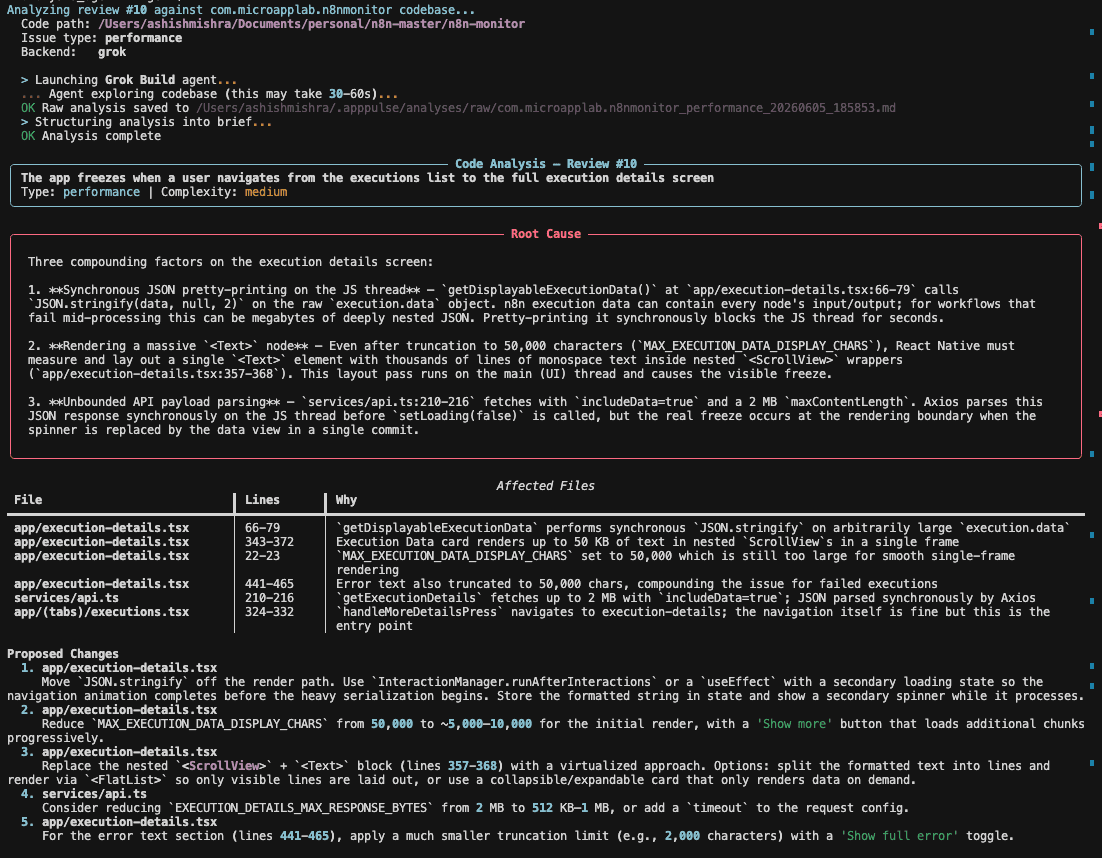
Stage 5: Codebase Analysis (Optional but Powerful)
For bug issues, a second LLM pass searches the codebase for relevant files (using the extracted keywords and functional area), reads them, and generates a root-cause hypothesis:
### Codebase Analysis (Auto-generated)
**Likely root cause**: `ImageUploadService.kt:142` allocates the full
bitmap in memory before compression. On Android 15's stricter memory
limits, images >10MB trigger OOM. The catch block at line 156 handles
IOException but not OutOfMemoryError.
**Suggested fix**: Use BitmapFactory.Options.inSampleSize to downsample
before loading. Add OutOfMemoryError to the catch block.
**Files to modify**: ImageUploadService.kt, ImageCompressor.kt
For feature requests, it analyzes the architecture and generates an implementation plan — which modules to extend, what new components are needed, estimated complexity.
This works because the LLM has access to the full repository (the pipeline runs as a GitHub Action inside the repo) and the review classification already narrows down the functional area to search.
How This Compares to Existing Tools
The analysis core — classify reviews, detect sentiment, cluster topics — is well-trodden ground. BERTopic, VADER, and LLM classification all solve this reliably. The open-source repos mentioned earlier do this well.
What none of them do:
| Capability | Existing Repos | This Pipeline |
|---|---|---|
| Official API ingestion | No (assume CSV exists) | Yes |
| Scheduled continuous sync | No (one-shot) | Yes |
| Device/OS/version correlation | No | Yes (Google Play) |
| GitHub issue creation | No | Yes |
| Issue deduplication via embeddings | No | Yes |
| Codebase-aware analysis | No | Yes |
| Threshold-based alerts | No | Yes |
The existing repos answer "what are users saying?" This pipeline answers "what should my team work on next — and here's the ticket."
Running It
The whole thing runs as a GitHub Actions workflow in the same repo as your app code:
name: Review Intelligence Pipeline
on:
schedule:
- cron: '0 */6 * * *' # Every 6 hours
workflow_dispatch:
jobs:
process-reviews:
runs-on: ubuntu-latest
permissions:
issues: write
contents: read
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- uses: actions/setup-python@v5
with:
python-version: '3.12'
- run: pip install -r review-pipeline/requirements.txt
- name: Run pipeline
env:
GOOGLE_PLAY_SERVICE_ACCOUNT_JSON: ${{ secrets.GP_SA_JSON }}
ASC_ISSUER_ID: ${{ secrets.ASC_ISSUER_ID }}
ASC_KEY_ID: ${{ secrets.ASC_KEY_ID }}
ASC_PRIVATE_KEY: ${{ secrets.ASC_PRIVATE_KEY }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: python -m review_pipeline.main
Secrets go in your repo's Settings → Secrets. The GITHUB_TOKEN is auto-provided by Actions with the issues: write permission.
Cost at 1,000 new reviews/day: ~$3-5/month for LLM classification. Everything else is free (GitHub Actions free tier, SQLite, open-source libraries).
Watch Out For
- Google Play's 7-day window. If your cron breaks for more than a week, you'll miss reviews permanently. Add monitoring on the Action itself.
- Apple gives no device data. Your device-correlation analysis will be Google Play-only unless you bring in crash reporting data from another source.
- Clustering threshold tuning. Start with 0.85 cosine similarity and adjust. Too low and unrelated reviews get grouped; too high and you get duplicate issues for the same problem phrased differently.
- LLM classification isn't perfect. Sarcastic reviews ("great app, crashes every 5 minutes, love it") can fool simple prompts. Add examples of sarcasm to your classification prompt.
- Rate limits everywhere. Google Play allows ~200 GET requests/hour. App Store Connect rate-limits after heavy pagination. Add exponential backoff.
Takeaways
- The official APIs (Google Play Publisher API + App Store Connect API) give you everything you need for your own apps. Don't scrape.
- The analysis layer (sentiment, classification, clustering) is a solved problem. Use an LLM for classification — it's cheaper and more accurate than building custom NLP.
- The real value isn't in the analysis. It's in the bridge from "customer said X" to "GitHub Issue #238 with device data, severity label, and a code-level hypothesis."
- At ~$3-5/month for LLM costs and zero infrastructure beyond GitHub Actions, this is dramatically cheaper than any SaaS alternative — and you own all the data.